概览
对抗搜索是人工智能中专门研究零和博弈 (Zero-Sum Games) 的领域。在这类游戏中,一个玩家的收益必然等于另一个玩家的损失,双方处于竞争对抗关系。典型的例子包括井字棋、国际象棋、围棋等。
与之前学习的寻路或CSP问题不同,对抗搜索的环境是动态的和充满恶意的——环境中存在一个或多个理性的对手,其目标就是阻止我方达成目标。因此,我们的决策不仅要考虑自身利益,还必须预测并反制对手的最佳策略。
对抗搜索的核心挑战在于处理一个会思考、会反击的对手,而不是一个静态或随机的环境。算法的目标是在假设对手每一步都做出最优选择的前提下,为自己找到一个能保证“最坏情况下”最好的走法。
- 游戏树: 将整个游戏的博弈过程表示为一棵树,节点是棋局状态,边是合法的走法。每个节点会有一个“效用值”(Utility)。
- 玩家角色:
- 我方:目标是让最终的效用值最大化。
- 对手:目标是让最终的效用值最小化。
Minimax
Minimax是解决对抗搜索问题的基石算法,完美地体现了博弈论中的理性决策过程:最大化(Maximize) 己方收益,同时假设对手会最小化(Minimize) 己方收益。
算法流程
Minimax算法的 效用函数 (Utility Function) 只作用于游戏终局(叶子节点),给出一个明确的分数。例如:赢=+1, 输=-1, 平局=0。通过对游戏树进行一次完整的深度优先搜索,自底向上地计算每个节点的值:
-
在MAX层,节点的值等于其所有子节点中的最大值。
-
在MIN层,节点的值等于其所有子节点中的最小值。 最终,根节点(当前局面)的下一层节点会各自有一个Minimax值,MAX玩家选择那个值最大的走法即可。
评估函数
对于国际象棋、围棋等复杂游戏,我们无法搜索到游戏终点。因此,我们需要一种方法,当搜索到达预设的深度上限 (Cutoff Depth) 时,对当前的非终局状态进行打分。此时评估函数会取代真实的效用函数,为当前棋局估算一个分数,代表该局面对于MAX玩家的优势程度。
设计
通常是多个特征 (Features) 的加权线性函数: evaluation(s) = w1 * f1(s) + w2 * f2(s) + ...
-
f(s)是从状态中提取的特征,如:- 子力价值: 我方棋子总分与对方的差值。
- 机动性: 我方棋子的可移动步数。
- 中心控制: 对棋盘中心区域的控制力。
-
w是每个特征的权重,代表其重要性。
设计评估函数是游戏AI开发中最具挑战性的部分。它需要深厚的领域理论知识,并结合大量的实验来调整权重。
def minimax(state, player, depth): # 设置深度限制
# 基准情况:如果游戏结束,返回效用值
if state.is_terminal():
return utility_func(state)
# 达到深度限制:启用评估函数
if depth == LIMIT_DEPTH:
return evaluation(state)
successors: set[State] = get_successors(state)
# 递归步骤
if player == 'MAX':
best_value = max(minimax(s, 'MIN', depth+1) for s in successors)
else:
best_value = min(minimax(s, 'MAX', depth+1) for s in successors)
return best_value
Alpha-Beta 剪枝
原始的Minimax算法虽然能找到最优解,但它必须遍历整个游戏树,在复杂游戏中计算量大到无法接受。Alpha-Beta剪枝是其最核心的优化,能够在不影响最终结果的前提下,安全地“剪掉”大量无需探索的博弈分支。
核心思想
在搜索过程中,如果发现某个分支再怎么走,其结果也肯定不会比我们已经找到的某个选择更好,那么这个分支就可以被忽略。
算法在自顶向下搜索时,维护两个关键变量:
-
α (Alpha): MAX玩家的“最佳保底收入”。在搜索路径上,MAX玩家目前能确保得到的最低分数。初始为$-\infty$。
-
β (Beta): MIN玩家的“最高可接受成本”。在搜索路径上,MIN玩家愿意让MAX得到的最高分数。初始为$\infty$。
剪枝条件: 当 $\alpha \ge \beta$ 时,可以进行剪枝。 这个条件意味着,MAX玩家的 保底收入 已经超过了MIN玩家愿意付出的 代价 。MIN玩家绝不会让游戏朝这个分支发展,因为它有其他选择能把MAX的得分压得更低(低于$\alpha$)。
def alpha_beta_search(state, player, depth, alpha=-math.inf, beta=math.inf):
if state.is_terminal():
return utility_func(state)
# 达到深度限制:启用评估函数
if depth == LIMIT_DEPTH:
return evaluation(state)
successors: set[State] = get_successors(state)
if player == 'MAX':
best_value = -infinity
for s in successors:
value = alpha_beta_search(s, 'MIN', depth+1, alpha, beta)
best_value = max(best_value, value)
alpha = max(alpha, best_value) # 更新MAX的最佳保底
if alpha >= beta:
break # Beta 剪枝 (MIN玩家不会选择这条路)
return best_value
else:
best_value = +infinity
for s in successors:
value = alpha_beta_search(s, 'MAX', depth+1, alpha, beta)
best_value = min(best_value, value)
beta = min(beta, best_value) # 更新MIN的最高可接受成本
if alpha >= beta:
break # Alpha 剪枝 (MAX玩家有更好的选择)
return best_value
Alpha-Beta剪枝的效率极大地依赖于走法的排序。如果能优先探索“最佳”的走法,剪枝的效率会达到最大化。在理想情况下,它能将搜索深度加倍,是实现强大AI的关键技术。
Expectimax
Minimax和Alpha-Beta非常适合处理确定性的游戏。但如果游戏中包含随机性(如掷骰子、发牌),或者对手并非绝对理性,我们就需要期望最大化搜索(Expectimax)。
核心思想
Expectimax在游戏树中引入了第三种节点类型:机会节点 (Chance Node)。这种节点的值不是通过max或min计算,而是通过其所有可能结果的期望值 (Expected Value) 来计算。
其中 $i \in$get_successors(Node),$P(i)$ 是出现第 $i$ 个随机结果的概率。
def expectimax(state, player, depth):
if state.is_terminal():
return utility_func(state)
# 达到深度限制:启用评估函数
if depth == LIMIT_DEPTH:
return evaluation(state)
# 机会节点:计算所有随机结果的期望值
if player == 'EXPECT':
successors: set[float, State] = get_successors(state)
next_player = get_player(state, player)
total_value = 0
for prob, next_state in successors:
total_value += prob * expectimax(next_state, next_player, depth+1)
return total_value
else ... #按照minimax + alpha_beta
直接计算金钱或分数的期望值,有时会得出反直觉的结论(如 圣彼得堡悖论 )。
一个更高级的决策智能体,追求的不是“期望价值”最大化,而是“期望效用 (Expected Utility)”最大化。通过 引入非线性的 效用函数 ,我们可以模拟人类的风险规避等复杂决策行为,让AI的选择更“理性”和“人性化”。
蒙特卡洛树搜索
当游戏的分支因子过大(如围棋),且很难设计出精确的评估函数时,一种基于随机模拟的现代方法——蒙特卡洛树搜索(MCTS)便应运而生。它是AlphaGo等现代棋类AI的核心引擎。
核心思想
MCTS放弃了对整个游戏树的确定性遍历,转而通过大量的随机模拟(Rollouts) 来评估一个走法的好坏。基本思路是:对于一个走法,我们从它导致的局面开始,让两个“无脑”的玩家随机下棋直到游戏结束,然后统计成千上万次这种随机模拟的胜率,以此来判断该走法的好坏。
步骤
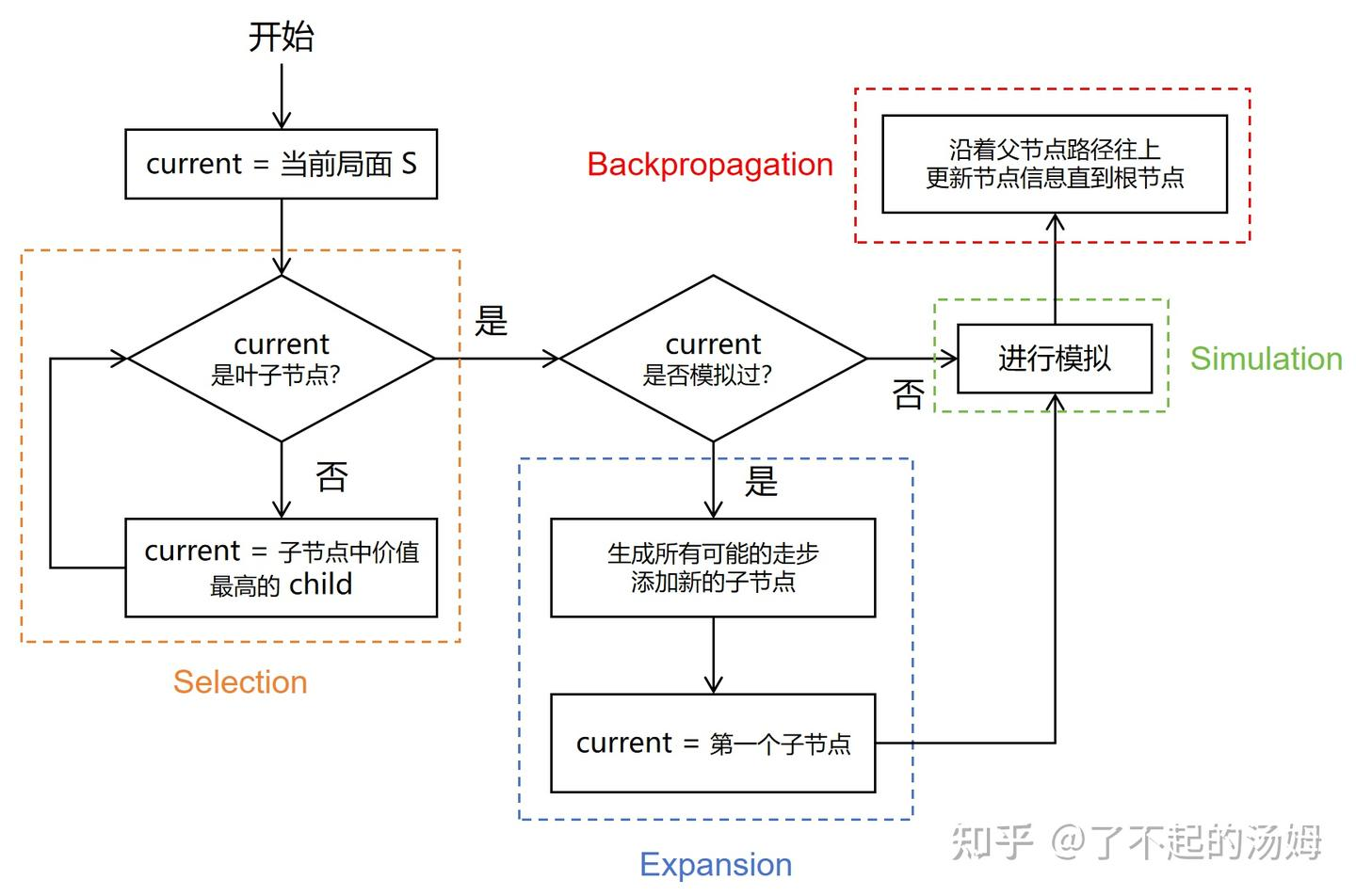
MCTS通过一个不断迭代的循环,智能地增长一棵非对称的游戏树,将算力集中在“更有前途”的分支上。
-
选择 (Selection): 从根节点开始,根据一个策略(如UCT公式)选择一个最有潜力的叶子节点。
-
扩展 (Expansion): 如果这个叶子节点不是终局,就为它创建一个或多个新的子节点。
-
模拟 (Simulation): 从一个新创建的子节点开始,进行一次快速的、完全随机的“玩到死”模拟(Rollout)。
-
反向传播 (Backpropagation): 将模拟的结果(赢或输)沿着路径传回根节点,更新路径上所有节点的统计数据(如胜利次数、访问次数)。