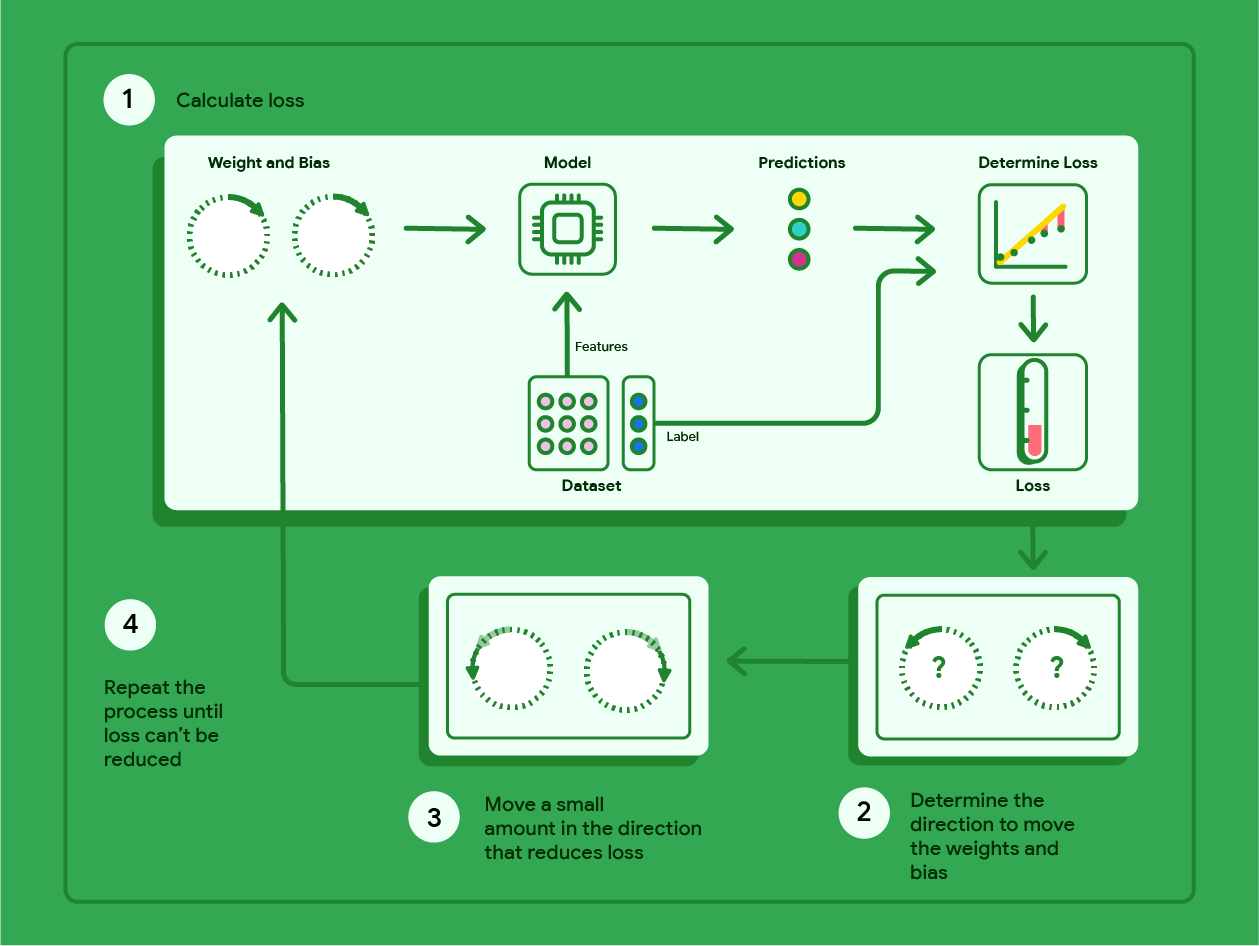
梯度下降法用于更新线性回归模型中的参数($\boldsymbol{w},b$), 公式为
\[w'_i=w_i-\alpha\dfrac{\partial J(\boldsymbol{w},b)}{\partial w_i},\quad b'=b-\alpha\dfrac{\partial J(\boldsymbol{w},b)}{\partial b}\]其中$J(\boldsymbol{w},b)$是成本函数,偏导数主要控制梯度下降的方向,$\alpha$ 为参数(学习率),控制参数的变化幅度。
优化方法
小批量梯度下降
小批量随机梯度下降(Mini-batch gradient descent)每次选取一小部分数据来计算梯度并更新参数。
工作流程
- Shuffle:在每个训练周期 (Epoch) 开始前,将训练集打乱。(增加训练随机性)
- 划分批次 (Batching):将打乱后的数据集按指定大小(
batch_size)切分成若干个小批量。 - 循环迭代 (Iterate):
- 取出一个小批量数据。
- 计算这个小批量数据的平均梯度,更新模型的权重和偏置。
- 重复以上过程,直到遍历完所有的小批量数据,完成一个 Epoch。

动态学习率
学习率 α 是梯度下降中重要的超参数,一个固定不变的学习率存在一个两难问题:
- 如果设置得太大,训练初期下降很快,但后期会在最优点附近剧烈震荡,难以精确收敛。
- 如果设置得太小,虽然能保证最终收敛,但整个训练过程会异常缓慢。
动态学习率(也称学习率调度, Learning Rate Scheduling)的思想是:让学习率在训练过程中自动发生变化,以适应不同的训练阶段。目前常用的策略是Adam(Adaptive Moment Estimation)优化器
Adam 优化器的核心思想是:为网络中的每一个参数,都独立地、智能地计算出一个动态的学习率。
-
核心组件一:动量 (Momentum) Momentum 算法在更新参数时,不仅仅考虑当前的梯度,还会计算一个梯度的“指数移动平均值”。简单来说,它会把过去一段时间的梯度方向也考虑进来,如果梯度方向持续保持一致,更新的步伐就会越来越大,从而加速收敛。
-
核心组件二:自适应学习率 (Adaptive Learning Rate) Adam 会跟踪每个参数梯度的平方值的“指数移动平均值”。这个值可以看作是该参数更新频率或幅度的历史记录。Adam 用这个值来归一化 (normalize) 每个参数的更新步长。梯度历史值大的参数,其更新步长会被相应地缩小。
在每次参数更新时,Adam:
-
计算梯度的带偏置校正的第一阶矩估计(动量项)。
-
计算梯度的带偏置校正的第二阶矩估计(自适应项)。
-
用这两个值来计算最终的参数更新量。