参考视频:
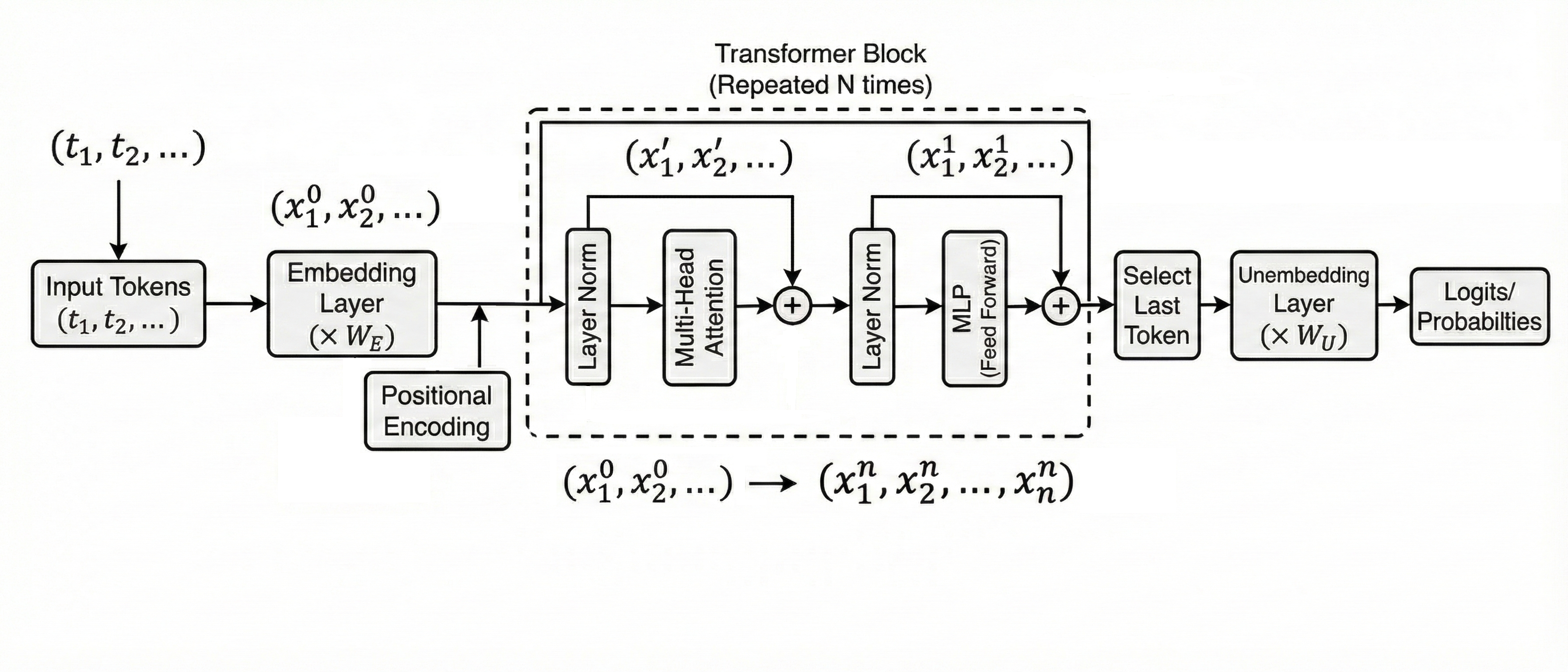
Token Embedding
LLM会内置一个词表 $E\in \mathbb{R}^{V\times d}$ (其中 $d$ 为模型维度), 负责将输入Tokens映射到一个线性空间中。含义相近的Token在线性空间中的距离尽可能相近。
Transformer 的架构中没有内置处理序列顺序的机制,需要通过位置编码显式地为模型提供序列中单词的位置信息。
一个好的编码机制应符合如下原则:
- 无论序列长度如何,每个位置编码长度唯一
- 编码位置关系应尽可能简单(最好是线性的)
- 编码可泛化到任意长序列(即使长度超过训练时的序列长度)
正弦位置编码
pos位置的Token映射后第2i, 2i+1维的分量为
\[\begin{aligned} &PE(pos,2i)=\sin\left(\dfrac{pos}{10000^{2i/d}}\right)\\ &PE(pos,2i+1)=\cos\left(\dfrac{pos}{10000^{2i/d}}\right) \end{aligned}\]缺点:采用绝对位置pos编码,若推理长度大于训练长度,效果较差
RoPE
$q \cdot e^{i\theta}$ 相当于将向量 $q$ 旋转 $\theta$ 角度。
RoPE(旋转向量编码) 将向量两两分组,每组在一个二维子空间内旋转: 对于向量组 $(q_0, q_1)$ 和位置 $m$,RoPE 将其视为复数,乘以 $e^{im\theta}$:
\[\begin{pmatrix} q_0' \\ q_1' \\ \vdots \\ q_{d-1}' \end{pmatrix} = \begin{pmatrix} \cos m\theta_0 & -\sin m\theta_0 & 0 & 0 & \cdots \\ \sin m\theta_0 & \cos m\theta_0 & 0 & 0 & \cdots \\ 0 & 0 & \cos m\theta_1 & -\sin m\theta_1 & \cdots \\ \vdots & \vdots & \vdots & \vdots & \ddots \end{pmatrix} \begin{pmatrix} q_0 \\ q_1 \\ \vdots \\ q_{d-1} \end{pmatrix}\]Transformer 层
Transformer层主要由Attention层和MLP(多层感知机)组成。Token序列经过Embedding层后,得到的矩阵 $\boldsymbol{X}\in \mathbb{R}^{l\times d}$ 将输入至attention层中。其中$d$为模型维度
LayerNorm
为了使注意力相关矩阵的更新更加平稳,向量经过模型每一层的Attention和MLP之前都需要进行归一化操作。现代模型主要进行RMSNorm:
\[\bar{x}_i = \frac{x_i}{\sqrt{\frac{1}{d} \sum_{j=1}^d x_j^2 + \epsilon}} \cdot g_i\]其中$\epsilon$ 是一个很小的数,防止除0操作,$g_i$为可训练参数
Self-Attention
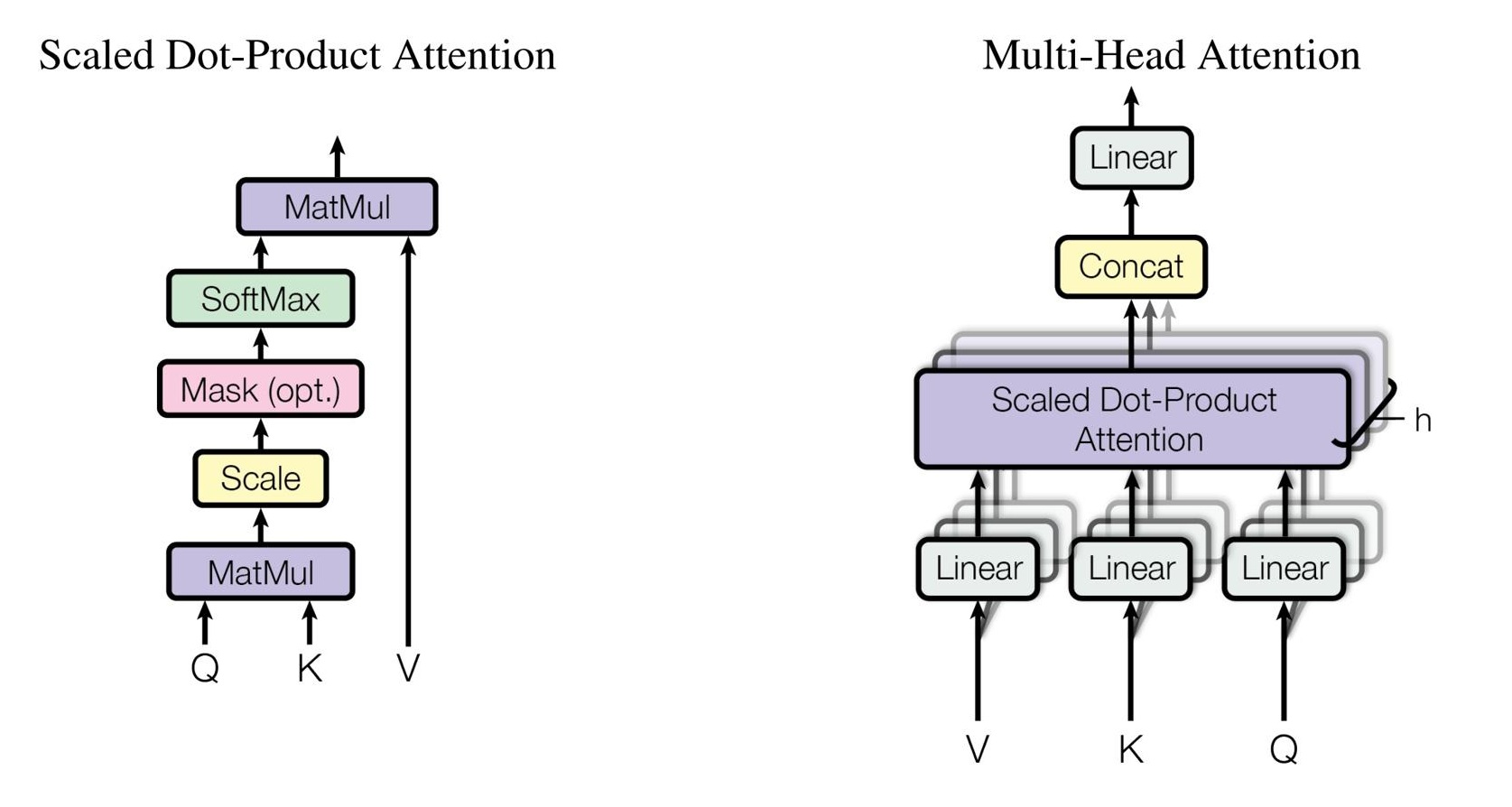
$X$ 并行通过三个线性层: \(Q = X W_Q, \quad K = X W_K, \quad V = X W_V\) 其中 $W \in \mathbb{R}^{d \times d_k,Q,K,V \in \mathbb{R}^{l \times d_k}}$
- Query
- Key
- Value
含义:代表当前 Token 在当前上下文中的搜索意图。 “为了理解我自己,我需要从上下文中关注哪些信息”。
例子:在句子 "The cat ate the fish" 中,当处理单词 "ate" 时,它的 Query 向量可能会表达一种向量特征,大致意思是: “我在找一个动作发出者(谁吃的?)”。
含义:代表当前 Token 作为被查询对象时的索引特征。
作用:用于和 Query 进行匹配。暴露这个词的某些特定属性,以便其他词的 Query 能够找到。
例子:以上述句子为例,单词 "cat" 的 Key 向量可能编码出: “名词,动物,主语”。 当 "ate" 的 Query(找主语)遇到 "cat" 的 Key(我是主语候选人)时,匹配度会很高。
含义:代表当前 Token 内部需要被传递的信息。
作用:一旦匹配成功(Q 和 K 算出高权重),Value 就会被提取并融合到上下文中。
1.MatMul: $Q \cdot K^T$ 衡量了$Q$ 和 $K$ 每行向量在方向上的相似程度(两个词在多大程度上是相关的)
2.Scale: 在应用Softmax之前,需要对 $Q \cdot K^T$ 的结果进行缩放,防止数值膨胀和梯度消失问题。
3.Masking: 在decoder-only的模型(如GPT)中,训练(和推理)过程,我们不希望 某个Token 注意到它之后的内容。
在 Sequence Mask 中,将 scale 后的矩阵变为三角矩阵(将所有Token之后的位置的值变为 $-\infty$,应用Softmax之后变为0),得到最后的匹配“分数”
4.Softmax: 将匹配分数转化为概率分布
5.Matmul: 用算出来的概率权重,对 Value 矩阵进行加权求和,得到的结果包含了新的上下文语义信息。
多头注意力
由于词语天然具有多义性,我们需要有不同的并行注意力头,用来匹配词语可能的不同语义。
假设矩阵 $\boldsymbol{X}$ 进入 一个有 $n$ 个注意力头的 attention 层,则输出
\[\boldsymbol{X'}=\boldsymbol{X}+\sum_{i=1}^{n}\text{Attention}(Q_i, K_i, V_i)\]Softmax 函数强制注意力分数是非负的且总和为 1。当前的 Query Token 找不到与其强相关的 Key Token 时,模型需要将这些“剩余”的注意力分数分配给某个地方 。 由于第一个 Token 对所有后续 Token 都是可见的,模型倾向于将其作为一个特定位置来存储这些冗余的注意力分数 。因此模型常将不成比例的注意力分配给首个 token。
对注意力输出引入门控机制,即 $$ \text{Attention}^{'}=\text{Attention}⊙σ(\boldsymbol{X}W_θ) $$ (⊙为逐点相乘,$W_\theta$为可训练参数)能够过滤掉无关的上下文信息,提高训练稳定性
FNN
前馈神经网络 (Feed-Forward Network, FFN)主要由两层的多层感知机(Multilayer Perception, MLP)实现。所有Token并行通过(对序列中的每一个 Token 独立地进行变换)。
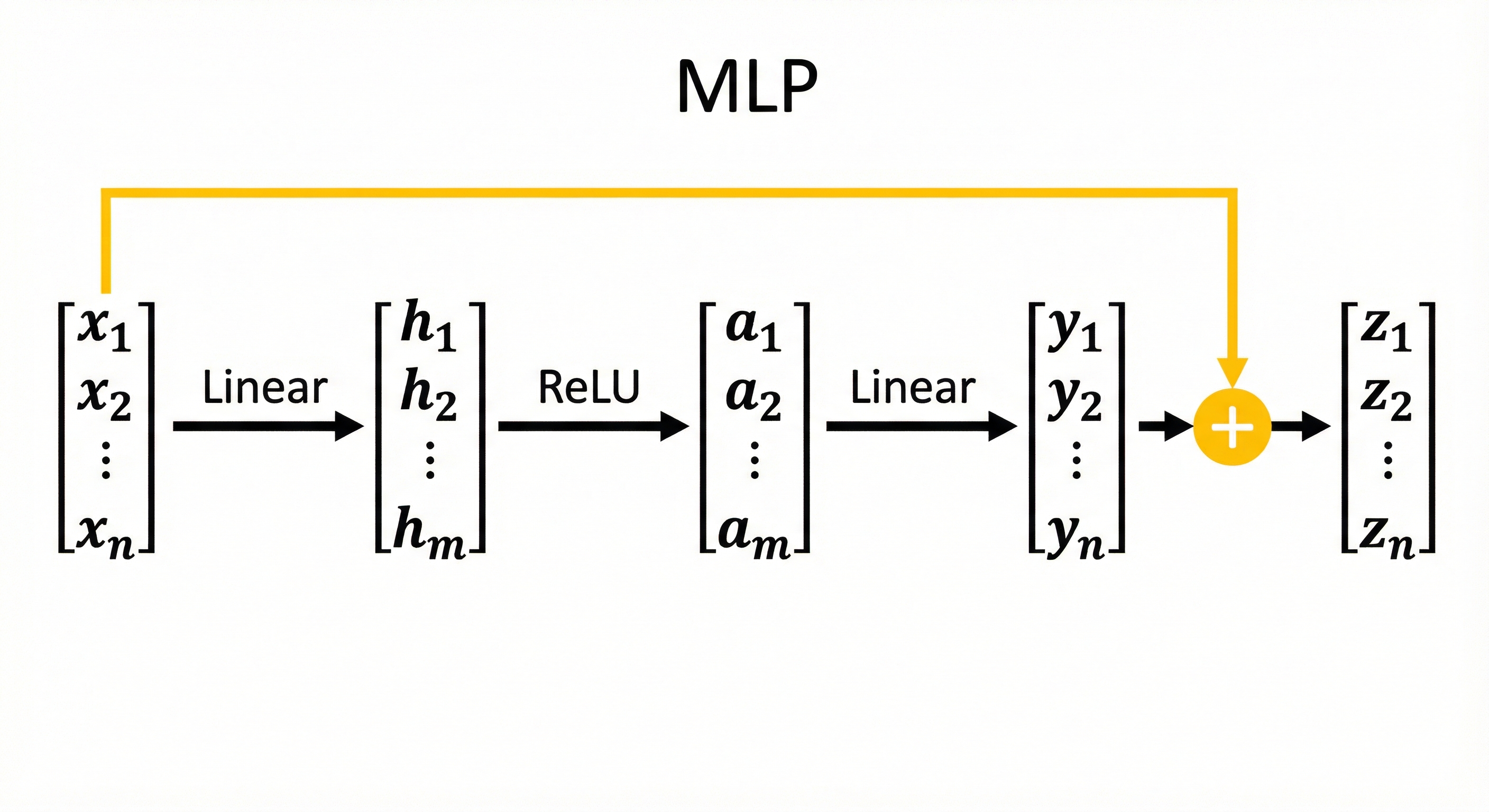
MLP的第一层进行升维,通过激活函数进行非线性变换,然后在第二层降维,最后与输入相加。
FFN 的第一层 ($W_1$) 可以看作是 Key (模式识别器):它负责探测输入向量中是否包含某种特定的语义模式。
FFN 的第二层 ($W_2$) 可以看作是 Value (内容生成器):一旦第一层探测到了某种模式,第二层就会把对应的“新信息”或“知识”注入到输出向量中。
Unembedding
经过 $N$ 层 Transformer Block 的处理,我们得到了最后一个 Token 的隐藏状态向量 $h_{final} \in \mathbb{R}^d$。 这个向量被认为浓缩了对下一个词的所有预测信息。
- Final Normalization
在现代模型 Pre-Norm 结构中,残差路径(Main Path)从未被归一化过,数值可能随着层数累积而漂移。进行归一化将高维特征向量拉回标准分布,确保后续线性投影的数值稳定性。
\[h_{norm} = \text{RMSNorm}(h_{final})\]- Linear Projection (线性投影)
模型维护一个巨大的矩阵 $W_U \in \mathbb{R}^{d \times V}$,其中 $V$ 是词表大小。
\[z = h_{norm} \cdot W_U\]这里 $z \in \mathbb{R}^V$ 被称为 Logits(未归一化的对数概率)。
$W_U$ 的每一列可以看作是词表中某个词的“原型向量”(Prototype Vector)
假设$W_U$有一列为$w_{apple}$,点积操作 $h \cdot w_{apple}$ 本质上是在计算:**当前的向量 $h$ 与“苹果”这个词的特征向量有多相似?
- Softmax (概率生成)
将 Logits 转化为概率分布(和为 1,且非负)。
\[P(w_i | \text{context}) = \text{Softmax}(z_i) = \frac{e^{z_i}}{\sum_{j=1}^V e^{z_j}}\]在推理阶段,Logits 会先经过一系列后处理 (Logits Processing),再 Softmax。
- Temperature (温度):$z_i = \dfrac{z_i}{T}, T<1$ 放大高分值的差异(更确定),$T>1$ 缩小差异(更随机)
- Top-k Sampling: 只保留概率最高的 $k$ 个词,将剩余词的概率置为 0。
- Top-p Sampling: 将排序后的概率累加,直到累加值刚刚超过 $P$。保留这些词,其他的置为 0。
注:在工程实现中,Top-k/Top-p 实现为将低概率的 Logits 设为 $-\infty$
- 随机解码(Stochastic Sampling):Softmax后,模型根据概率分布抽取一个Token进行输出。