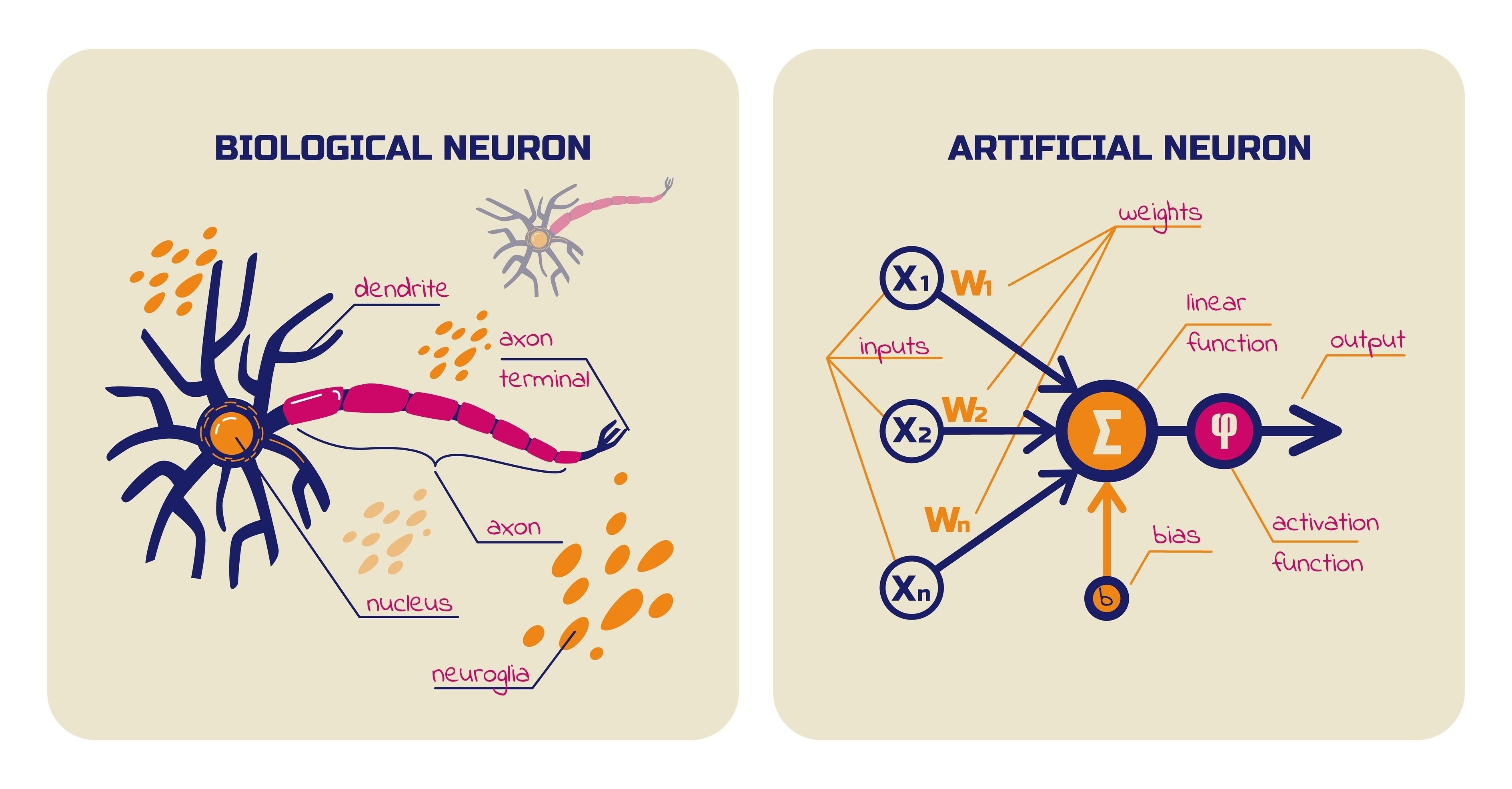
人工神经网络 (Artificial Neural Network, ANN)由输入层,隐藏层(Hidden layer)和输出层组成,每一层包括若干个神经元。每个神经元接收来自前一层神经元的输出 $\boldsymbol{x}$ 。首先进行仿射变换(类似线性回归):
\[z=\boldsymbol{xw^T}+b\]$\boldsymbol{w},b$ 即是需要进行学习的参数。
然后通过激活函数进行非线性变换 $a=g(z)$ ,并传递给下一层神经元。常用的激活函数为ReLu函数: $\text{Relu}(z)=max(0,z)$
如果没有激活函数,最终输出等同于对输入进行若干次仿射变换的复合,其结果仍为仿射变换。此时,神经网络和逻辑回归/线性回归完全相同。
通过激活函数进行非线性变换,神经网络能够进行更为复杂的拟合。(如使用ReLu函数时,结果为分段函数,每一段都是一个仿射函数)
学习过程
- 前向传播(Forward Propagation):输入数据 $X$ 进入输入层,经过隐藏层的一系列计算(每个隐藏层执行 $\text{Output} = g(\boldsymbol{w^T}\cdot\text{Input}+b)$ ),在输出层的的每个神经元产生 $\hat{y}$
- 计算损失:将 $\hat{y}$ 和真实标签 $y$ 比较,通过损失函数计算损失
- 梯度下降:利用反向传播(Backpropagation)计算出损失函数对于网络中每一个权重 $w$ 和偏置 $b$ 的梯度并更新
神经网络会循环以上步骤若干次。每一次循环,神经网络的参数都会被微调,使得它做出的预测越来越接近真实值。就这样,网络逐渐“学会”了如何从输入数据中提取模式并做出准确的预测。
反向传播
对于每个神经元,我们需要通过梯度下降更新 $\boldsymbol{w},b$ .因此,我们需要计算出$\dfrac{\partial J}{\partial \boldsymbol{w}},\dfrac{\partial J}{\partial b}$ .根据偏导数计算的链式法则,我们可以反向逐层计算(查看详细过程),得到(上标代表层标号)
\[\frac{\partial J}{\partial \boldsymbol{w}^i} = \delta^i \cdot (\boldsymbol{a}^{i-1})^T\]其中,对于一个 $n$ 层神经网络,误差项 $\delta^i$ 的计算方式如下(其中 $g$ 为当前层的激活函数):
-
对于输出层 ($i=n$):
\[\delta^n = \dfrac{\partial J}{\partial \boldsymbol{a}^n} \cdot\ (g^n)'\] -
对于隐藏层 ($i < n$):
\[\delta^i = \left( \sum_j w_{j}^{i+1} \delta_j^{i+1} \right) \cdot(g^i)'\]
Example:多类别
下面以多类别分类为例,介绍人工神经网络的代码实现。
训练数据:
X_train: Tensor of shape(N, C) # 共有N组数据,C个特征Y_train: Tensor of shape(N, ) # 每组标签为真实类别
手搓版
我们只依赖矩阵乘法、逐元素激活与交叉熵损失。设网络层维度数组为 dims=[d_0, d_1, ..., d_L],其中 d_0 是输入特征数,d_L 是类别数,其余为隐藏层宽度。
class ScratchNN:
def __init__(self, dims, lr=0.1):
self.W = [randn(dims[i-1], dims[i]) * eps for i in range(1, len(dims))]
self.b = [zeros(dims[i]) for i in range(1, len(dims))]
self.lr = lr
def _relu(self, x):
return max(x, 0)
def _relu_grad(self, x):
return (x > 0).astype(float)
Softmax
\[\text{Softmax}(\boldsymbol{z}) = \dfrac{e^{\boldsymbol{z}-\max (\boldsymbol{z})}}{\sum e^{z_i}}\] def _softmax(self, z):
z -= max(z, axis=1, keepdims=True)
exp_z = exp(z)
return exp_z / sum(exp_z, axis=1, keepdims=True)
前向传播
def forward(self, x_batch):
acts = [x_batch]
preacts = [None]
for W, b in zip(self.W, self.b):
z = acts[-1] @ W + b
preacts.append(z)
a = z if W is self.W[-1] else self._relu(z) # 最后一层直接输出
acts.append(a)
return acts, preacts
loss
\[\text{loss}= -\dfrac{1}{N} \sum_{i=1}^{N} \log(\hat{y}_{i})\] def loss(self, logits, labels):
probs = self._softmax(logits) # logits为最后一层输出的激活值
ce = -mean(log(probs[range(len(labels)), labels]))
return ce, probs
反向传播
在反向传播过程中,从后往前对W和b计算梯度。
def backward(self, acts, preacts, labels, probs):
grads_W, grads_b = [], []
grad = probs
grad[range(len(labels)), labels] -= 1
grad /= len(labels)
for i in reversed(range(len(self.W))):
grads_W.insert(0, acts[i].T @ grad)
grads_b.insert(0, grad.sum(axis=0))
if i > 0:
grad = (grad @ self.W[i].T) * self._relu_grad(preacts[i])
return grads_W, grads_b
参数更新 & 训练
def step(self, grads_W, grads_b):
for i in range(len(self.W)):
self.W[i] -= self.lr * grads_W[i]
self.b[i] -= self.lr * grads_b[i]
def train(self, dataloader):
for x_batch, y_batch in dataloader:
acts, preacts = self.forward(x_batch)
loss, probs = self.loss(acts[-1], y_batch)
grads_W, grads_b = self.backward(acts, preacts, y_batch, probs)
self.step(grads_W, grads_b)
log(loss)
库函数版
一些超参数:
k_foldsepochs:训练周期weight_decay:L2正则化率
1.使用 torch.nn 构建神经网络
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from sklearn.model_selection import KFold
class TorchNN(nn.Module):
"""
一个使用 torch.nn.Module 构建的两层神经网络。
结构: Input -> Linear -> ReLU -> Linear -> (Logits)
"""
super(TorchNN, self).__init__()
# 定义第一层:线性变换
self.layer1 = nn.Linear(input_dim, hidden_dim)
# 定义第二层(输出层):线性变换
self.layer2 = nn.Linear(hidden_dim, output_dim)
a_1 = nn.ReLu(self.layer1(x))
# -> (batch_size, hidden_dim)
scores = self.layer2(out)
scores = self.layer2(out)
# -> (batch_size, output_dim)
return scores
2.训练和k折交叉验证
# --- 初始化K折交叉验证 ---
# 使用scikit-learn的KFold
kfold = KFold(n_splits=k_folds, shuffle=True, random_state=42)
fold_accuracies = []
# --- 开始K折交叉验证 ---
for i, (train_ids, val_ids) in enumerate(kfold.split(X_train)):
print(f"--- 第 {i+1}/{k_folds} 折 ---")
# --- 数据准备 ---
X_train_batch, y_train_batch = X_train[train_ids], y_train[train_ids]
X_val, y_val = X_train[val_ids], y_train[val_ids]
# --- 初始化模型、损失函数和优化器 ---
# 为每一折重新初始化模型
model = TorchNN(
input_dim=n_features,
hidden_dim=32, # 隐藏层神经元数
output_dim=n_classes
)
# PyTorch的CrossEntropyLoss内置了Softmax,因此网络末尾不需要加Softmax
criterion = nn.CrossEntropyLoss()
# 使用Adam优化器,并传入weight_decay实现L2正则化
optimizer = optim.Adam(model.parameters(), weight_decay=weight_decay)
# --- 训练循环 ---
for epoch in range(epochs):
model.train() # 将模型设置为训练模式
# 1. 前向传播
outputs = model(X_train)
# 2. 计算损失
loss = criterion(outputs, y_train)
# 3. 反向传播和优化
optimizer.zero_grad() # 清空之前的梯度
loss.backward() # 计算梯度
optimizer.step() # 更新权重
# --- 在验证集上评估 ---
model.eval() # 将模型设置为评估模式
with torch.no_grad(): # 在评估时不需要计算梯度
val_outputs = model(X_val)
# 获取预测结果 (获取概率最高的类别的索引)
_, predicted = torch.max(val_outputs.data, 1)
correct_predictions = (predicted == y_val).sum().item()
accuracy = correct_predictions / y_val.shape[0]
fold_accuracies.append(accuracy)
print(f"第 {i+1} 折的验证准确率: {accuracy:.4f}\n")
分类
按网络结构,神经网络有以下几个主流类别。
- CNN (Convolutional Neural Network, 卷积神经网络)
- RNN (Recurrent Neural Network, 循环神经网络)
- GAN (Generative Adversarial Network, 生成对抗网络)
- Transformer