有监督学习(Supervised Learning)是机器学习中的一种类别,输入数据包括 特征(x) 和 标签(y),主要分为 回归 和 分类 两类。
数据预处理
当数据有多个特征时,为了避免量纲差异造成某个特征占据主导地位,会进行特征缩放。一种常见的方法是标准化(Standardization)。
标准化
标准化的目标是将特征变为均值为0,方差为1的分布。
\[x'=\dfrac{x-\mu}{\sigma}\]其中 $x$ 为原始特征值,$\mu$ 为平均数,$\sigma$ 为样本标准差。
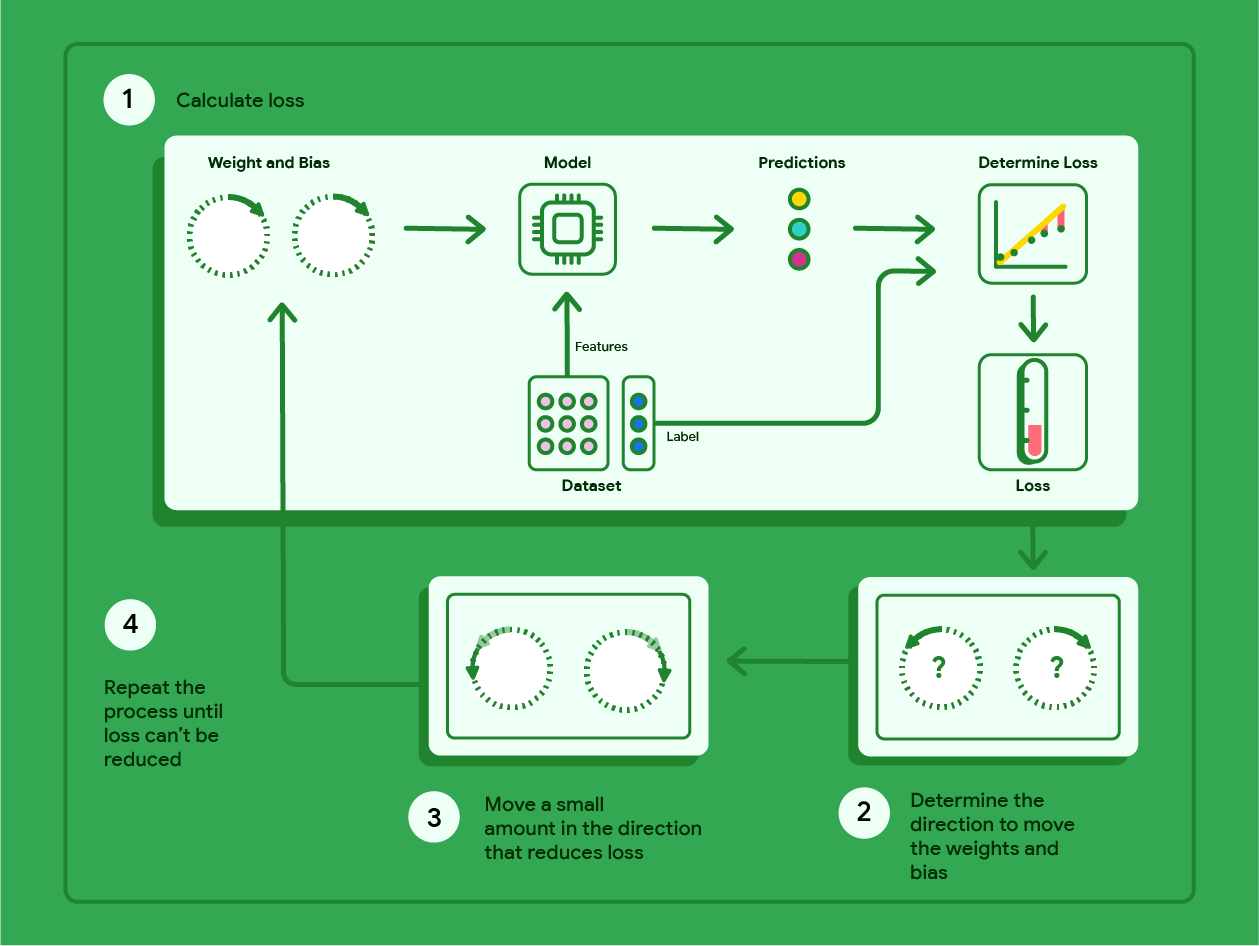
训练过程
- 确定初始 $\boldsymbol{w},b$ 的值
- 计算成本函数(Cost)。
为了防止过拟合,可以在成本函数中添加 $L_2$ 正则项 $\displaystyle\lambda\sum w^2$ ($\lambda$称为正则化率)。这样处理可以减小较高次数的项的系数。
- 利用梯度下降更新 $\boldsymbol{w},b$
- 重复步骤2~3若干次,得到最终 $\boldsymbol{w},b$ 的值
线性回归
预测公式
线性回归的输出为连续的值,其预测公式为\(\hat{y}=\boldsymbol{w}^T\boldsymbol{x}+b\)
可以利用多项式组合自行创造一些新的特征,如 $x_1^2, x_2x_3$ 等,从而达到形式上的非线性拟合
成本函数
线性回归的成本函数一般采用均方误差公式(其中 $m$ 为样本量):
\[cost=\dfrac{1}{2m}\sum (y-\hat{y})^2\]逻辑回归
预测公式
逻辑回归实际上属于分类任务,其输出为一系列离散的值,预测公式对线性回归的预测公式进行更多处理。
- 对于二元分类任务,需要将线性回归的值映射到0~1区间,然后以某个值(如0.5)为界确定预测标签。常用的一个映射函数是Sigmoid函数,它实际上代表$P(y=1)$
预测公式为
\[\hat{y}=\dfrac{1}{1+e^{-(\boldsymbol{w}^T\boldsymbol{x}+b)}}\]- 对于多元分类任务,通常采用神经网络架构,映射函数主要采用Sigmoid函数的推广形式:Softmax函数。
Softmax
在多元分类任务中,原始预测输出为一个分数列表,我们需要变换为概率分布列表,代表每个类别的概率,然后选取最大值作为最终预测。
为了防止原始分数列表 $\boldsymbol{z}$ 中有极端数字,造成后续计算溢出,通常会将 $\boldsymbol{z}$ 中的数据减去 $\boldsymbol{z}$ 中的最大值,即
\[\boldsymbol{z}_{\text{stable}}=\boldsymbol{z}-max(\boldsymbol{z})\]然后应用Softmax函数
\[\text{Softmax}(\boldsymbol{z}_{\text{stable}})=\dfrac{e^{\boldsymbol{z}_{\text{stable}}}}{sum(e^{\boldsymbol{z}_{\text{stable}}})}\]成本函数
逻辑回归一般采用对数损失函数(交叉熵损失函数),形式为:
- 二元分类
- 多元分类
最大似然估计是一种估计模型参数的方法, 目标是 找到能让“观测数据最可能出现”的参数值。 换句话说,我们假设数据是某个概率模型生成的,然后反过来找“哪个参数最可能产生这些数据”。
形式上,如果我们有样本 $(\boldsymbol{x}_1, y_1), \ldots, (\boldsymbol{x}_m, y_m)$,我们想最大化所有样本的联合概率(即最大化“似然函数” $L(w)$):
$$ L(w) = P(y_1,\ldots,y_m \mid \boldsymbol{x}_1,\ldots,\boldsymbol{x}_m; w) $$因为多个样本是独立的,我们可以写成乘积:
$$ L(w) = \prod_{i=1}^m P(y_i \mid \boldsymbol{x}_i; w) $$通常我们会取对数方便求导,得到对数似然函数:
$$ \ell(w) = \sum_{i=1}^m \log P(y_i \mid \boldsymbol{x}_i; w) $$逻辑回归假设:给定输入 $\boldsymbol{x}$,输出标签 $y \in \{0,1\}$ 服从伯努利分布
$$ \hat{y}=P(y=1 \mid \boldsymbol{x}) $$所以对于一个样本:
$$ P(y \mid \boldsymbol{x}; w) = \hat{y}^y (1 - \hat{y})^{1 - y} $$(这个公式能统一地表示 $y=1$ 和 $y=0$ 两种情况。)
带入对数似然函数中,得到:
$$ \ell(w) = \sum_{i=1}^m \left[ y_i \log\hat{y} + (1 - y_i) \log(1 -\hat{y}) \right] $$我们在训练时最小化它的相反数,即:
$$ J(w) = -\ell(w) = \sum_{i=1}^m \left[ -y_i \log \hat{y}_i - (1 - y_i) \log (1 - \hat{y}_i) \right] $$